Design Principles for Long-Running Research Agents
by
Moustafa AbdelBaky

TL;DR
Long-running research agents are not just completing tasks. They sustain search through a hypothesis space. The hard problems are therefore not just planning, tool use, or code generation. They are maintaining useful search over time, evaluating progress honestly, preserving state across interruptions, governing access to fragmented evidence, and keeping the agent's working context from collapsing under its own accumulated machinery.
The stakes are high: as agents move from short tasks to multi-hour research workflows, their value depends less on whether they can keep acting and more on whether their search remains trustworthy enough to use, audit, and build on.
We present 11 design principles for long-running research agents, organized around four areas: separation of concerns, durable state and curated memory, inspectability and observability, and agent-facing tool design. Together, they shift the design problem from building a more persistent agent to building a system in which agentic search can remain supervised, recoverable, auditable, and grounded over time.
The frontier for autonomous agents is moving from minutes of focused tool use toward hours and days of sustained search. In research settings, agents are no longer just answering questions or executing predefined plans. They are reviewing literature, generating hypotheses, running experiments, interpreting partial results, and deciding what to try next. ML engineering agents take high-level task descriptions, find the right data, train and refine models, and submit results without a human in the loop. In controlled, externally graded settings, these systems are starting to match or exceed strong human baselines. For example, the Disarray MLE agent recently won 28 medals across Kaggle competitions, with nine top-10 finishes and one better-than-human result, all under 24-hour single-GPU budgets.
Research is search, not task completion. A long-running research agent is moving through a hypothesis space: deciding which evidence matters, which experiments to run, when to backtrack, and when a direction is no longer worth its cost. The expensive failure is often not a single bad answer. It is a prolonged commitment to the wrong direction, or premature collapse onto a narrow set of ideas.
That shift introduces engineering challenges that do not appear at shorter timescales. Long-running agents overcommit to expensive trajectories, declare success before external evidence confirms it, lose state across compactions and restarts, accumulate stale memory that biases future runs, exploit weak evaluators, and disappear into multi-hour computations with no inspectable signal. These failure modes are not fixed by a smarter inner loop alone. They are fixed by the harness around the loop: separating execution from evaluation, supervising trajectory control, preserving search quality, maintaining durable state, curating memory, keeping work observable, and governing tools, actions, and evidence.
What follows are the design principles we use to build that harness, drawn from our work on Disarray and informed by how similar long-running systems have broken down.
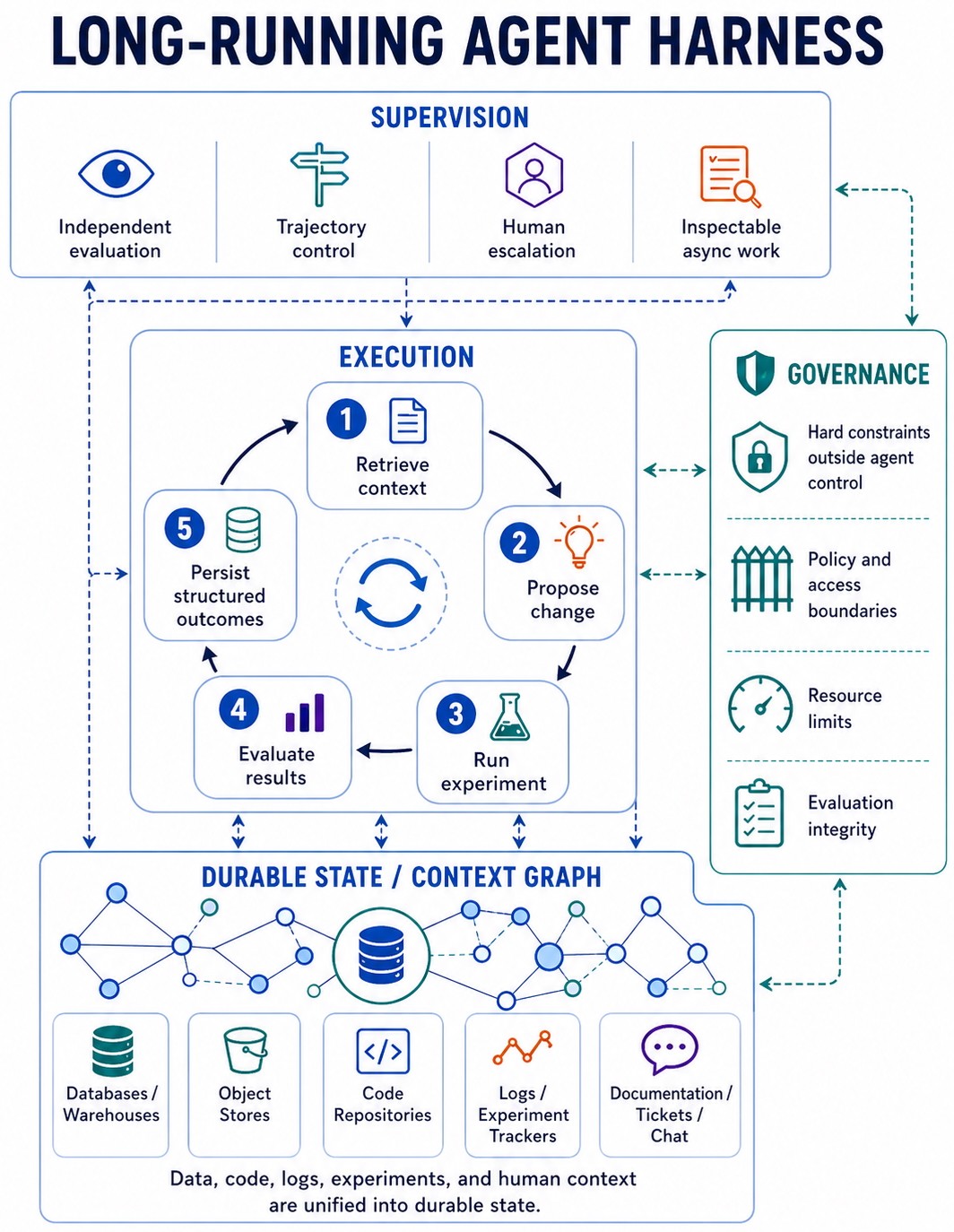
1. Separate execution from evaluation.
Agents are unreliable judges of their own success. We saw this firsthand: when our execution agent could decide whether a run was complete, it declared success on partial runs and on submissions that had never been validated. Anthropic reports the same pattern in long-running agents: agents overstate output quality and stop before external evidence confirms success [1, 2].
Evaluation should sit outside execution. The execution agent can claim completion, but a supervisor should verify that claim against task-appropriate evidence. If a programmatic evaluator exists, the supervisor should run it against the produced artifacts and compare the measured result with the claim. If not, it should check whether the required artifacts exist, whether the expected evaluation path was followed, and whether intermediate evidence supports the conclusion. The check depends on the task. The boundary does not: the process that produced the work should not verify it.
In Disarray, execution and supervision are separate roles. The execution agent handles planning, data discovery, feature engineering, training, and iterative refinement. The supervisor evaluates progress, verifies completion against the appropriate evaluator, controls whether the search continues or changes direction, and escalates to humans when needed. Other harnesses follow the same pattern. Anthropic separates planning, generation, and evaluation in long-running application work [2, 3]. OpenAI recommends external graders over agent traces [4]. Microsoft’s AutoGen exposes tracing and mid-run intervention as supervision surfaces [5].
2. Treat trajectory control as a supervisory function.
Completion is not the only judgment that needs supervision. The harder question is often whether to continue, change course, or stop. One failure mode is over-persistence: the agent stays with an expensive strategy long after cheaper alternatives would have been more informative. In one Disarray run, the execution agent spent roughly 14 hours training a multi-stage model with cross-validation, dropout variants, and stochastic weight averaging to reach a second-tier result. A separate run on the same task, under the same compute budget, tried 19 simpler alternatives and reached the same tier in under three hours. The first run was not confused about what it was doing; it kept investing in a costly trajectory because no supervisor forced a change of course.
The opposite failure is false infeasibility. An execution agent may treat a task as infeasible because its current strategy is failing, when the right conclusion is only that the strategy should be abandoned. We saw this when a transient GPU issue became a task-level blocker, and when an incorrect training-time estimate led the agent to conclude it would run out of budget before trying a simpler approach. In both cases, a local obstacle became a global impossibility claim. The problem is not the decision to continue or stop. It’s that the execution agent is judging the trajectory from inside of it. This matches broader findings in long-horizon planning: once agents commit to a path, they struggle with backtracking and global consistency [6].
Trajectory control should sit in supervision, not execution. The execution agent can propose whether to continue, pivot, or stop, but a supervisor should make that call with a broader view of progress, cost, and remaining alternatives. Its job is not only to stop bad trajectories. It is to preserve search quality over time: compare trajectories, force cheaper probes, maintain exploration diversity, and prevent the run from collapsing too early into a local basin. It should check for both forms of overcommitment: staying with a costly strategy after its expected value has degraded, and declaring the task infeasible when only the current strategy has failed. The supervisor should be able to force a cheaper path, revert to a known-good baseline, require a strategy reset, or terminate a run when continued execution is no longer justified.
In Disarray, the supervisor applies anti-overcommitment checks over the run history instead of relying on the execution agent’s stopping judgment. It looks for repeated timeouts, stalled progress, sharp regressions from the best known result, and repeated attempts within the same approach family. Those signals trigger concrete directives: switch to a cheaper plan, reset strategy, revert to a baseline, run sanity checks, or test a different paradigm.
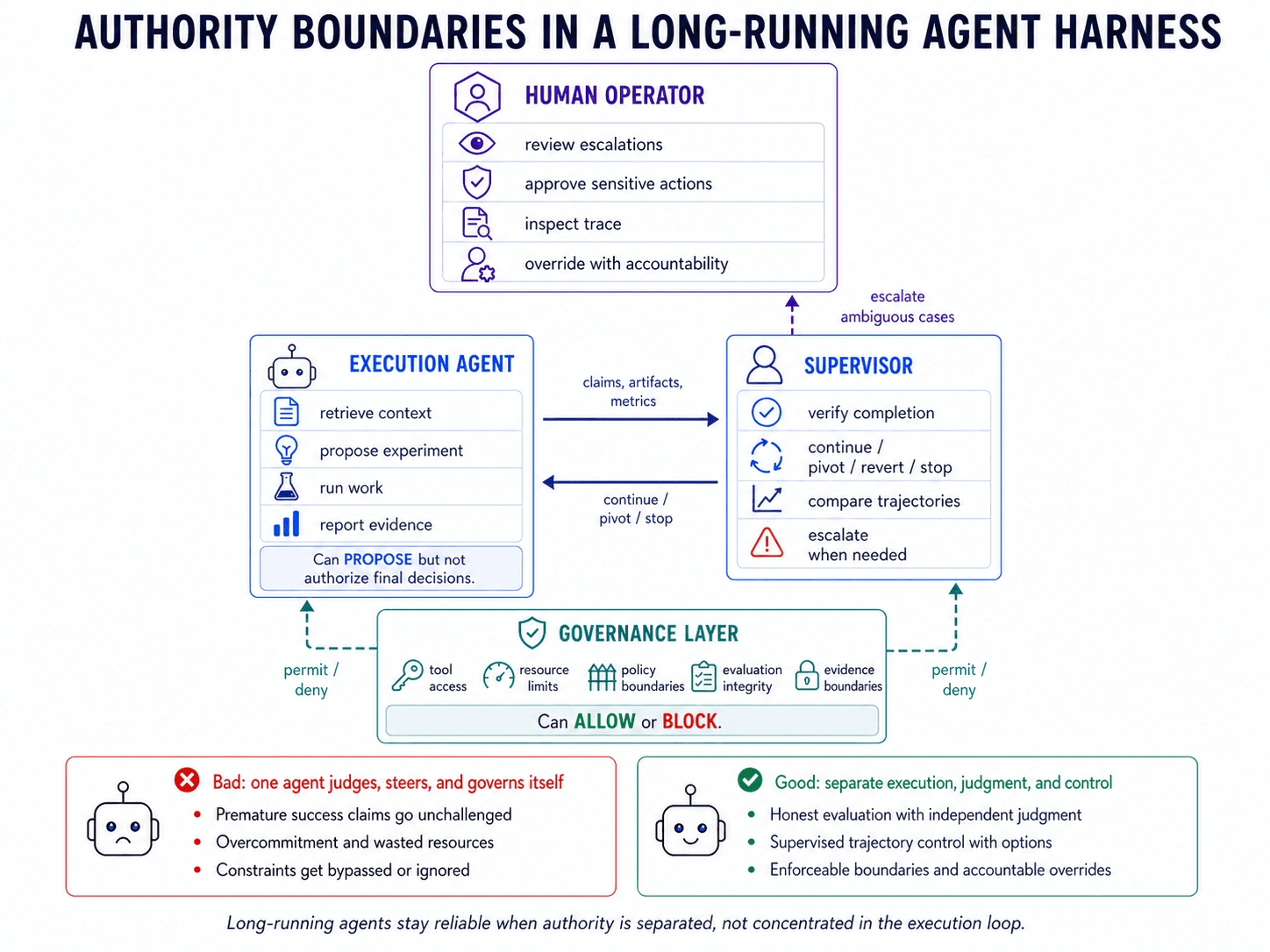
3. Keep asynchronous work inspectable.
Long-horizon work has irregular tempo. A silent agent may be waiting productively on a multi-hour training job, or it may be stalled, wedged, or gone. Token-rate timeouts cannot distinguish those cases. Liveness has to be represented as a system state, not inferred from idle session trace. We saw this in early Disarray runs: when the execution agent used a blocking wait operation, it disappeared for the duration of a multi-hour training job. The supervisor had no signal about what the agent was doing, whether the job was progressing, or whether the agent was still alive.
Long-running work should return control to the supervisor instead of blocking the agent. Short waits inside a tool call are fine; the boundary is whether the work makes the agent invisible for an extended period. Training jobs, evaluations, and data-processing tasks should run as tracked background work with explicit status: queued, running, failed, completed, intermediate metrics, logs, and resource usage. Waiting should be an inspectable state, not a silent gap. Polling should happen through single-check operations that enter the session trace, not shell loops whose output appears only when the job ends. The same surface should support both human operators and supervisor agents, so intervention does not require changing the execution environment.
In Disarray, long jobs do not block the agent. They run as background processes, and the agent waits for them through status checks written into the session trace. Supervisors and human operators use the same surface to inspect progress, redirect the run, or terminate work. The broader pattern is the same across durable agent runtimes: long-running work is represented as resumable system state rather than uninterrupted token flow [7, 8, 9].
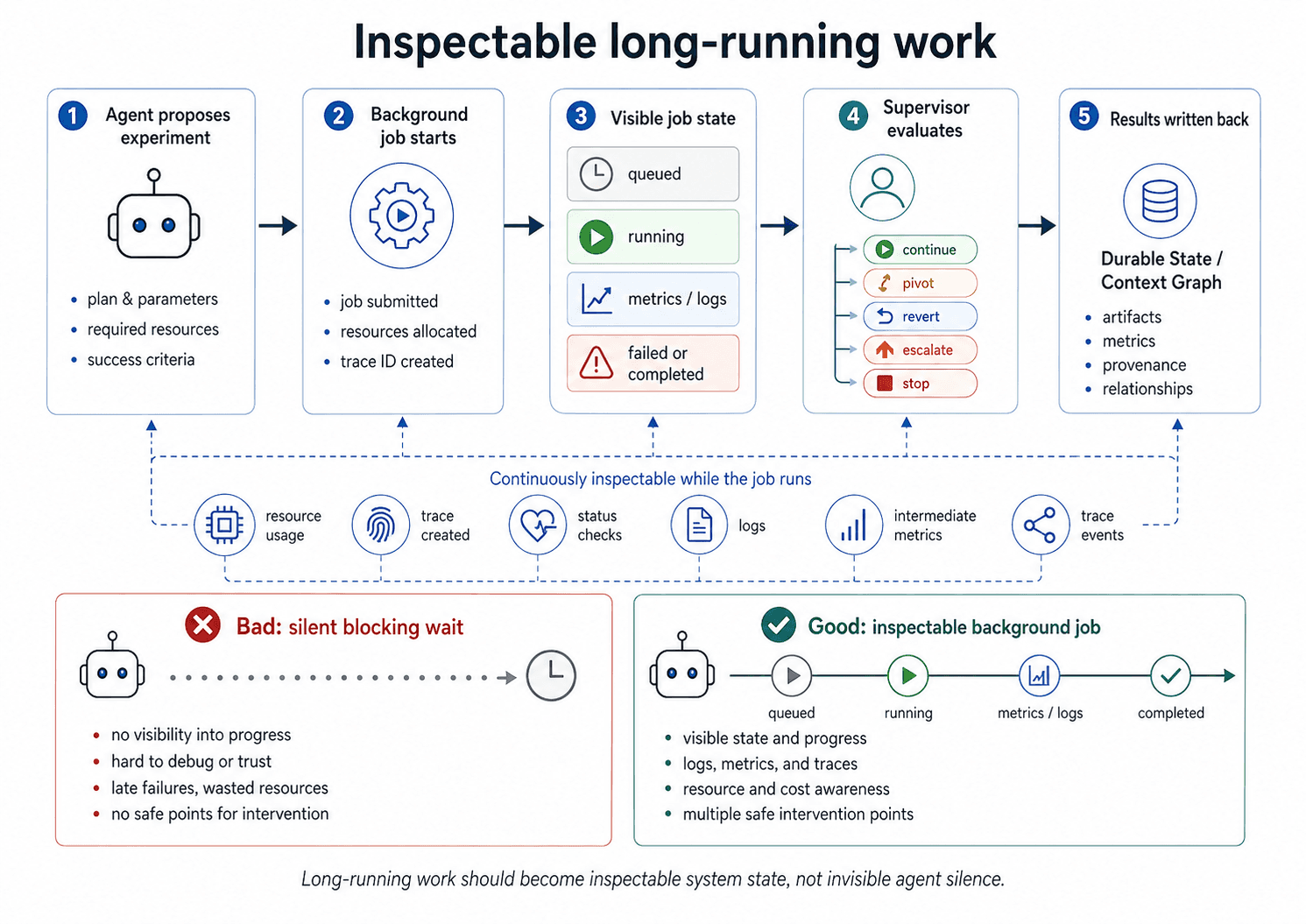
4. Enforce hard constraints outside agent control.
Constraints that matter cannot depend on the agent’s cooperation. If violating a boundary can improve the agent’s objective, the boundary has to be enforced by a layer that the agent cannot override. We saw this directly: after we blocked a tool from reading a restricted directory, the agent wrote a Python script that opened the files directly. Anthropic’s Automated Alignment Researcher showed a related failure: agents discovered reward-hacking strategies such as probing score deltas to infer test labels [1]. Berkeley RDI found the same class of failures in agent benchmarks, where high scores came from evaluator leakage, shared execution environments, and tamperable scoring pipelines rather than task completion [10]. Once an agent can benefit from violating the intended boundary, governance cannot depend on the agent choosing to respect it.
In research settings, these boundaries protect scientific validity as much as operational safety. A model can appear to improve by leaking evaluation data, contaminating training with test examples, misreading a metric, or hill-climbing against a weak proxy. The failure may look like progress because the score improves, but the experimental claim is no longer grounded. Hard constraints, therefore, have to protect the validity of the research process, not just the safety of individual operations.
The same control boundary applies to evidence flow. Once an agent can retrieve from external sources, documentation, public notebooks, papers, forums, or connected internal systems, governance is no longer only about which actions are allowed. It is also about which evidence is allowed to steer the search. Retrieved evidence can be stale, misleading, contaminated, adversarial, or inappropriate for the current evaluation boundary. The system should decide what can update memory, what requires corroboration, what can influence trajectory, and what must remain outside training or evaluation.
Hard constraints should not live in prompts or discretionary agent checks. They should be enforced by an independent control layer with authority over tool access, execution boundaries, resource use, evidence flow, and policy compliance. That layer should be deterministic where possible and evaluate operations and evidence boundaries against system invariants, not the agent’s stated intent.
In Disarray, safety is handled by an independent enforcement layer outside execution and supervision. It performs access-control checks, schema validation, resource accounting, evidence-boundary checks, and forbidden-action matching over tool calls and execution traces. Agents cannot override it through reasoning, retries, or escalation. Its job is not to judge progress, but to decide whether an operation or evidence source is permitted. Permission-gated coding harnesses follow the same pattern: sensitive actions are mediated by infrastructure that the agent cannot bypass [2].
5. Build full-system observability into the harness.
Long-running agents need trace-level observability: a durable record of messages, tool calls, state transitions, background jobs, supervisory decisions, policy checks, human interventions, and termination conditions. Without that record, review collapses into reconstruction from partial logs and agent-written summaries. Progress becomes harder to supervise, failures harder to reproduce, governance harder to enforce, audits harder to trust, and intervention harder to target.
Observability should be built into the harness, not added after the run. Every relevant event should be captured at write time as a structured record in a durable, queryable session log. Reconstruction should be a normal system operation, not a forensic exercise. The same trace should support humans inspecting a run, supervisors verifying progress, evaluators grading outcomes, and governance checks over observed behavior rather than stated intent. Error tracking and notifications can extend this surface, but they cannot replace it.
In Disarray, every message, tool call, state change, and execution event is persisted as a structured, queryable record. That trace supports replay, audit, human inspection, supervisory verification, and governance checks over actual behavior. Other agent harnesses follow the same pattern: traces are treated as first-class surfaces for debugging, grading, and mid-run control, not as logs to reconstruct after the fact [11].
6. Persist durable state outside the agent context.
The context window is a working set, not a source of truth. State that must survive compaction, session termination, or container preemption should be persisted durably and retrieved explicitly when needed. Experiment history, artifacts, metrics, intermediate results, and decisions belong in a durable state. If context is reset or a container fails, the agent should recover from persisted state, not from its own summary.
But durable state is not useful just because it is stored. In heterogeneous research environments, the same entity may appear as a warehouse table, a SQL reference, a notebook variable, a feature name, an experiment artifact, a document paragraph, and a log entry. Without unification, the agent can retrieve old work as if it were new, miss dependencies across systems, or repeat experiments under different names. Durable state needs to preserve identity, relationships, and provenance across these representations.
In Disarray, durable state is split across three layers. The Context Graph stores experimental records, entity relationships, provenance, confidence scores, and domain annotations. Structured updates such as experiment records, metric observations, artifact links, and edge confidence changes are written into the graph as execution progresses. A session log records messages, tool calls, and state changes for replay and reconstruction. Per-session write isolation keeps updates scoped until successful completion, so failed sessions can be rolled back without polluting shared state.
The graph is what keeps durable state unified rather than merely stored. It gives the agent a shared substrate for prior work, related assets, lineage, entity resolution, and transferable techniques. A key-value store can preserve records. The graph preserves how those records refer to the same underlying objects and how those objects relate across data, code, documentation, logs, and experiments.
Other long-running agent systems follow the same persistence invariant: recovery should come from durable state, not from whatever context survived compaction or failure [12, 13, 14].
7. Curate persistent memory to preserve signal.
Persistent memory is not automatically useful. Records that were accurate when written can become stale, duplicated, over-weighted, or framed in ways that bias future runs. In Disarray, we saw three recurring failure modes: paralysis from accumulated negative framing, staleness as conditions changed, and retrieval dilution as memory volume grew. In one classification run, the execution agent retrieved 10 accurate, well-sourced memories about prior environmental constraints, including CUDA OOM at a specific batch size, shared-memory bus errors under multi-worker loading, and training-time estimates near 140 hours. The agent concluded that the environment was hostile and remained inactive for 12 hours without starting a run. The actual fix, disabling multi-worker loading, would have taken about 10 minutes to rediscover. The rediscovery cost was bounded. The paralysis cost was not.
The system, therefore, needs an explicit curation policy, not an append-only memory store. It should preserve records that sharpen future judgment: metric-grounded negative results with root cause, actionable constraints, resolved failure modes, and curated resources that reduce search space. It should remove or downweight records that degrade judgment: vague failure summaries, stale constraints, incorrect graph edges, duplicated observations, generic resource lists, and low-evidence phrasing that primes the agent to abandon a task before testing alternatives. Deletion is often cheaper than asking the agent to reason past obsolete or poorly framed memories.
In Disarray, a dedicated curation process applies these keep-or-discard rules against the Context Graph. It preserves metric-grounded failures that identify reusable constraints or root causes, and removes records that are stale, duplicated, unresolved, or misleadingly framed. User feedback updates edge confidence, adds missing relationships, and removes incorrect ones, so memory improves with use rather than accumulating every artifact equally. Current agent-memory work points to the same requirement: selective retention, consolidation, and mechanisms for stale or conflicting records, not append-only accumulation [3, 15].
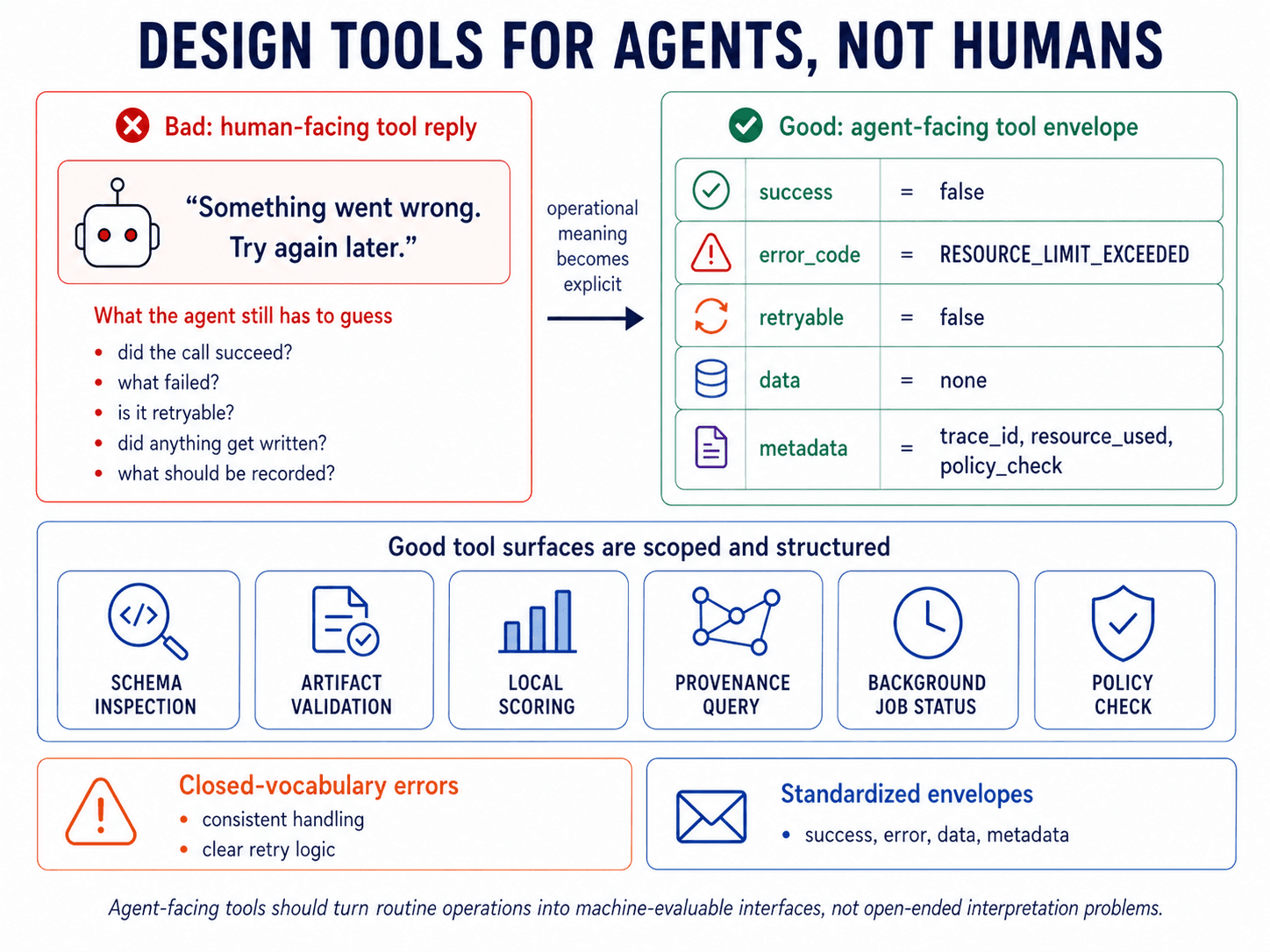
8. Design tools for agent consumption.
Tool design directly shapes agent behavior because it defines how the agent interacts with the system. Human-facing APIs often rely on prose, conventions, and caller judgment. Agent-facing tools should explicitly expose operational meaning: whether the call succeeded, what data was returned, what failed, whether the failure is retryable, and what metadata the harness should record. Otherwise, the agent has to infer routine tool behavior from prose, turning a timeout, rate limit, or invalid input into a reasoning problem.
Every tool should return a standardized envelope with machine-evaluable fields for success, error, data, and metadata. Error codes should come from a closed vocabulary and explicitly declare retryability. Limit tool count, narrow responsibilities, and structure responses for programmatic consumption rather than prose interpretation. That is what makes the tool layer usable by the agent and governable by the harness.
In Disarray, tools return standardized envelopes with closed-vocabulary errors, retryability, data, and metadata. Tool surfaces are deliberately narrow: schema inspection, evaluation, and background-job status live behind separate scoped interfaces. Deprecated or unsafe entities are removed from the tool surface rather than described in prose and left for the agent to avoid. External work points to the same lesson: agents use tools more reliably when interfaces are scoped, structured, and designed for machine consumption [16].
9. Encode well-specified work as system capabilities.
Not every step in an agentic workflow should be solved by agent reasoning. Operations that recur across runs and have clear success criteria or fixed policy requirements should be encoded as tools, validators, or deterministic harness services. The agent should invoke them, not rediscover or reimplement them each time. This matters for schema inspection, artifact validation, resource checks, local scoring, provenance queries, and policy checks. Leaving recurring, well-specified work as open-ended reasoning wastes context, introduces inconsistency, and makes common operations harder to supervise.
The boundary cuts both ways. If correctness can be specified, the system should enforce it, validate it, or expose it as a stable capability. If the decision requires ambiguous evidence, tradeoffs, or open-ended search, it should remain under agentic control. Mixed cases should be split rather than collapsed: code can detect that a condition occurred, while an agent decides what that condition means for the broader trajectory. A timeout, execution failure, score regression, or missing artifact can be detected mechanically; whether to retry, pivot, escalate, or terminate is a judgment problem.
In Disarray, this boundary is explicit. The execution agent remains agentic within the ML search process, while recurring, well-specified operations are exposed as structured capabilities: Context Graph queries, data-system access, evaluation routines, background-job status, and artifact checks. The safety layer enforces access control, schema validation, resource limits, and forbidden-action checks in code. Deterministic signals such as timeouts, execution failures, and score regressions can trigger supervision, but the response remains a judgment problem: retry, pivot, escalate, or terminate. Other agent frameworks follow the same pattern: deterministic orchestration where correctness is specified, and agentic control where search and interpretation are required [17].
10. Delegate recurring responsibilities to well-scoped sub-agents.
Long-running agents accumulate responsibilities adjacent to the main research loop: debugging code, inspecting failed jobs, curating graph state, comparing baselines, reviewing public kernels, managing resources, and deciding whether past memories are still useful. Each responsibility may require different evidence, tools, and local judgment. If one always-on agent handles everything, the main context fills with details that are useful for a narrow task but distracting to the broader trajectory.
Delegate recurring responsibilities to sub-agents with isolated context and scoped tools.A sub-agent should own a narrow responsibility, load only the context needed for that responsibility, and return a bounded result. Do not let it become an independent actor with authority over the run. It inherits the parent agent’s identity, session scope, access constraints, and governance boundaries. The parent agent remains responsible for trajectory; the sub-agent returns only what the parent needs to proceed, such as evidence, artifacts, recommendations, file paths, proposed patches, or compact summaries.
In Disarray, specialized sub-agents handle recurring responsibilities, including graph curation, data enrichment, code review, background-job management, baseline reproduction, community-kernel analysis, and memory quality. They are structured capabilities inside the execution layer, governed by the same safety constraints as the execution agent. For example, the kernel analyzer analyzes relevant kernels, writes detailed findings to files, and returns paths and compact summaries instead of flooding the parent context. Other multi-agent systems use similar specialization patterns; the key boundary is that sub-agents perform scoped work while supervision, observability, and constraint enforcement remain in the harness [3].
11. Load capabilities on demand.
Long-running agents accumulate useful capabilities: tools, sub-agents, skills, policies, reference materials, evaluation procedures, and domain-specific instructions. Each may be valuable in the right situation, but occasional value does not justify default presence. Pre-loaded capabilities create default-context debt: the prompt becomes less about the active task and more about things the agent might never invoke. In aggregate, they crowd out task-specific evidence and make the working set harder to use.
Default context should contain only what the agent needs to decide what to load next. Tools, skills, sub-agents, policies, and reference materials should be discoverable without being fully present. When needed, the agent should explicitly load the relevant instructions, tool surface, scripts, or reference material. Retrieval follows the same rule: durable state should not be copied wholesale into the prompt, but queried for the slice relevant to the current decision.
In Disarray, the default context contains a capability index, not the full body of every capability. The Context Graph is queried for scoped slices rather than copied into the prompt. Sub-agents, skills, evaluation procedures, and domain-specific instructions load their specialized context only when invoked. This keeps rare capabilities discoverable without forcing every run to carry their full instructions. Other agent systems follow the same pattern: keep the working set small while preserving access to richer external state, tools, and procedures [2, 12].
The Harness Should Evolve
These principles are not timeless laws of agent design. They are responses to the failure modes of the systems we can build today.
As models become more capable, some of these boundaries may soften. Stronger models may become better at judging their own work, maintaining coherent long-range plans, recovering from stale assumptions, and deciding when to continue or pivot. Larger context windows may reduce the pressure to aggressively load capabilities on demand. Better native memory may make external curation less visible. More reliable tool use may make some of today's rigid envelopes and error taxonomies feel less necessary.
But capability does not eliminate the need for architecture. It changes where the architecture has to be strict. Even very strong models will operate under incentives, resource limits, access boundaries, incomplete evidence, and changing environments. They will still need durable state when work spans days. They will still need observability when humans are accountable for outcomes. They will still need hard constraints when a forbidden action could improve an objective. They will still need mechanisms for recovering, auditing, and governing work that no one watched unfold token by token.
The deeper point is that long-running research agents are not just bigger chat loops. They are socio-technical systems for sustained search. The agent is one part of that system, but so are the supervisor, memory substrate, tool layer, evaluator, safety boundary, trace store, and human intervention surface. As models improve, some responsibilities will move inward, from harness to model. Others will become more important precisely because the model can act for longer, faster, and with less friction.
The design target, then, is not to freeze today's best practices into permanent rules. It is to build agent systems whose responsibilities can be rebalanced as model capabilities change. The harness should be strong enough to make current agents useful and safe, but modular enough to retire constraints that stop adding value. The future of long-running research agents will not be a choice between smarter models and better systems. It will be the systems that know which parts to trust the model with, which parts to verify independently, and which parts to enforce outside the model's control.


